|
Home | Publications | Google Scholar | GitHub | Project
|
|
In-network computing offloads server-based applications to programmable devices. However, network devices are very resource-constrained compared to servers. This project aims to scale in-network computing algorithms further via distributed deployment. This project can also be used as an extension of the in-network ML project. |
|
|
|
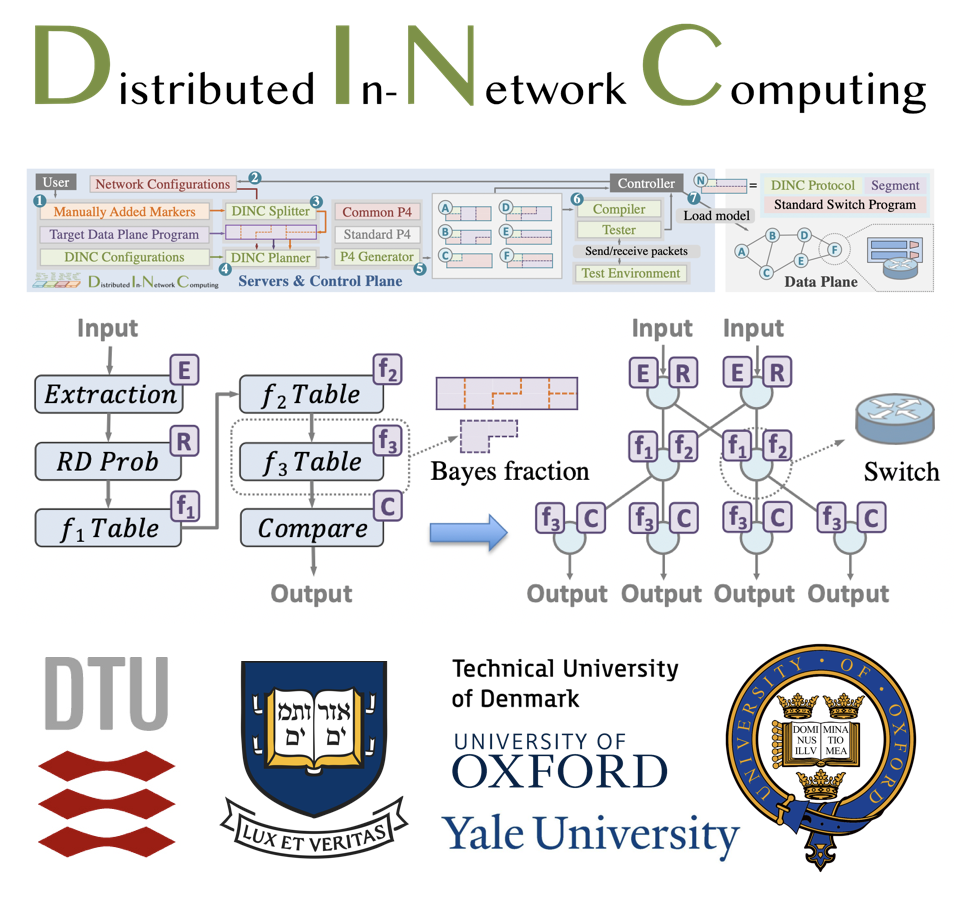
Changgang Zheng, Haoyue Tang, Mingyuan Zang, Xinpeng Hong, Aosong Feng, Leandros Tassiulas, and Noa Zilberman ACM CoNEXT'23 & Proceedings of the ACM on Networking, 2023 [Acceptance Rate: 24/129=18.6%] Paper | BibTex | Code Research has focused on enabling on-device functionality, with limited consideration to distributed in-network computing. This paper explores the applicability of distributed computing to in-network computing and presents DINC, a framework enabling distributed in-network computing, generating deployment strategies, overcoming resource constraints and providing functionality guarantees across a network. |

|
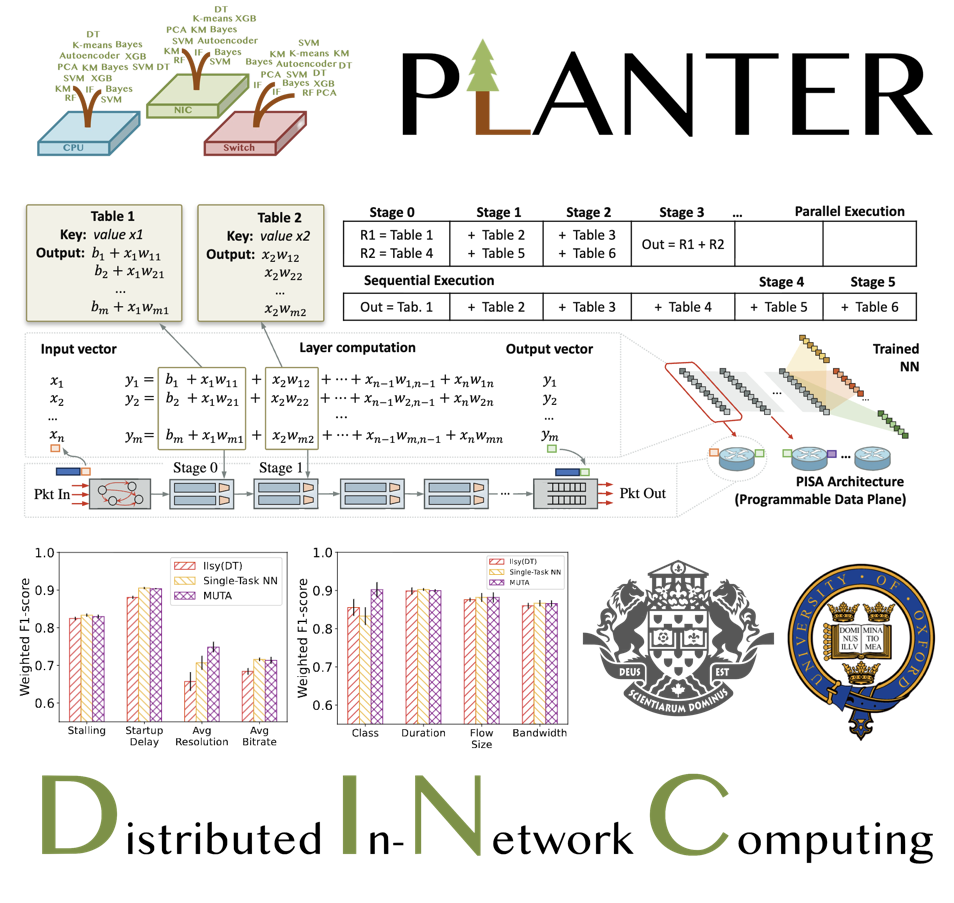
Kaiyi Zhang, Changgang Zheng, Nancy Samaan, Ahmed Karmouch, and Noa Zilberman IEEE HPSR 2025 [CCF B] [Best Paper Award] Paper | BibTex We introduce MUTA; a novel in-network multi-task learning solution. MUTA enables executing multiple inference tasks concurrently in the data-plane, without exhausting available resources. |
|
Kaiyi Zhang, Changgang Zheng, Nancy Samaan, Ahmed Karmouch, and Noa Zilberman IEEE Transactions on Network and Service Management (TNSM) Link | BibTex We introduce MUTA, a novel in-network multi-task learning framework that enables concurrent inference of multiple tasks in the data-plane, without exhausting available resources. MUTA enhances scalability by supporting distributed deployment, where different layers of a multi-task model can be offloaded across multiple switches. |